Setting the Scene
Year 2018 saw a critical partnership between Adobe & Microsoft to unite data, content and process and with this came a strategic direction for Adobe Managed Services. Adobe Managed Services[1] had been offering platform based services and although the platform was considered completely cloud agnostic, a lot of automation was built around AWS and business scaled up supporting several hundreds of customers on AWS platform.
Year 2018 saw a critical partnership between Adobe & Microsoft to unite data, content and process and with this came a strategic direction for Adobe Managed Services. Adobe Managed Services[1] had been offering platform based services and although the platform was considered completely cloud agnostic, a lot of automation was built around AWS and business scaled up supporting several hundreds of customers on AWS platform.
With the Adobe - Microsoft partnership, there was a clear direction for us to provide AEM Managed services platform on Azure. Systems were put in place immediately to bring on customers directly to AMS managed Azure systems. While this was a no-brainer, real value realization of partnership was to be seen when several key business moved from AWS hosting to Azure. With this came a clear business driver to start evaluating the various factors involved in lifting and shifting deployments from AWS to Azure.
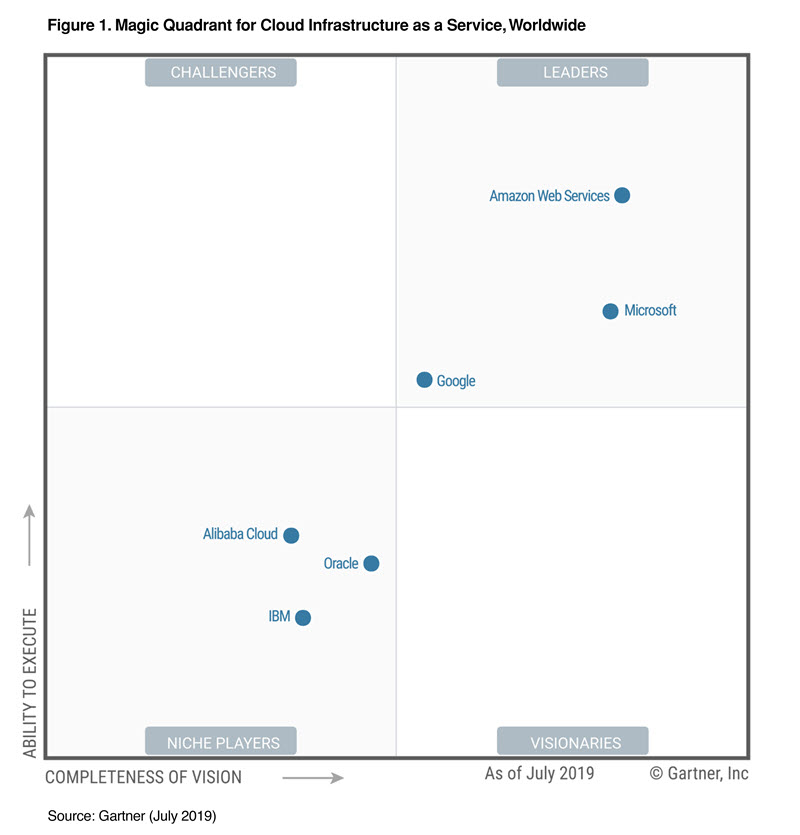
While Gartner sees Amazon far ahead leading the way, we also see Microsoft trending not too far behind. A detailed report [2] contains all the aspects that were considered while evaluating various players in this space.
AEM Architecture on AWS
While Gartner sees Amazon far ahead leading the way, we also see Microsoft trending not too far behind. A detailed report [2] contains all the aspects that were considered while evaluating various players in this space.
AEM Architecture on AWS
A typical architecture on AWS involves a dedicated VPC (Virtual Private Cloud) with EC2 instances deployed in individual subnets


The deployment represented here is a typical AEM Sites deployment and when we bring in Assets and Forms into mix we would see the inclusion of S3 or JE servers in the mix with a similar type of architecture. The server configurations are entirely based on the availability and typically are Amazon's General purpose EC2 instances which offers a balance of network, compute and memory resources for a typical AEM workload. They are using fourth generation of custom nitro cards and ENA device to deliver 100Gbps of network throughput to a single instance.
The load balancer is either a classic elastic load balancer or customer tend to use the application load balancer along with basic web application firewall rules attached to it to provide minimum protection to layer 7 traffic at the infrastructure's end point.
The above example serves simply as a reference and by no means refers to an actual customer deployment and the scope of this article would be to use this as a reference and map out a similar architecture in Azure and strategy for movement .
Mapping of Components
Al-Beruni et.al[3] has laid out a nice and easy to understand comparison of instance types between Azure and AWS. The DsV3 series of servers are designed for production workloads offering an ideal balance of compute, network throughput and memory in a similar comparison to the instance type of AWS.
Load Balancing: In comparison to Elastic Load balancer / Application load balancer, Azure AppGateway V2 provides similar capabilities including dynamic scaling, routing traffic at OSI Layer 7 and also similar protection with web application firewall with no additional cost. One of the main points of comparison is the number of sites that can be onboarded to ELB/ALB in comparison to AZGW. AWS ELB is first generation load balancer which does load balancing on OSI layer 4 and we can have only one domain mapping to the ELB while AWS ALB is based on OSI Layer 7, there is a hard limitation of hosting only 20 websites (HTTP&HTTPS) on a single ALB This certainly becomes a challenge with multi tenancy. Azure Gateway can host around 100 websites on the same instance.
One of the biggest draw back with AWS ELB is that customer can only have his WWW or Subdomain mapped to an ELB as they do not provide static IP associated with them. Only a DNS CNAME record can be added for ELB while ALB & Azure AppGateway provides a single static IP that can be added as a DNS A record for 100 different websites in the case of Azure AppGateway & 20 websites for ALB. This clearly is a blessing in disguise for customers who rely on multi-tenancy.
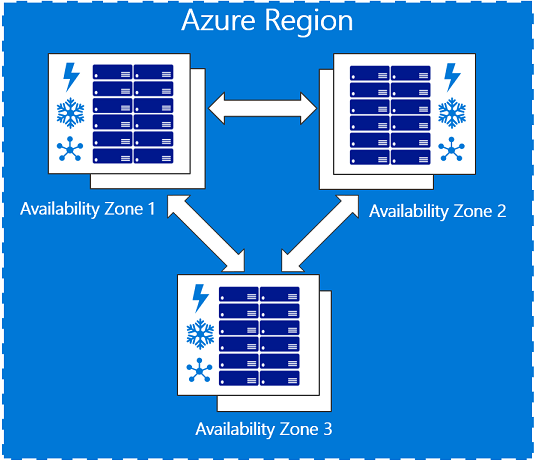
For a long time the concept of availability zones did not exist with Azure [4] and rather it was called update domain / fault domains, now these are integrated into availability zones. The whole requirement became crucial to provide high availability keeping in mind failures of datacenters. Azure also provides the capability of replicating data across the datacenters though keeping in mind AEM architecture, this may not be entirely relevant.
CDN(Content Delivery Network)
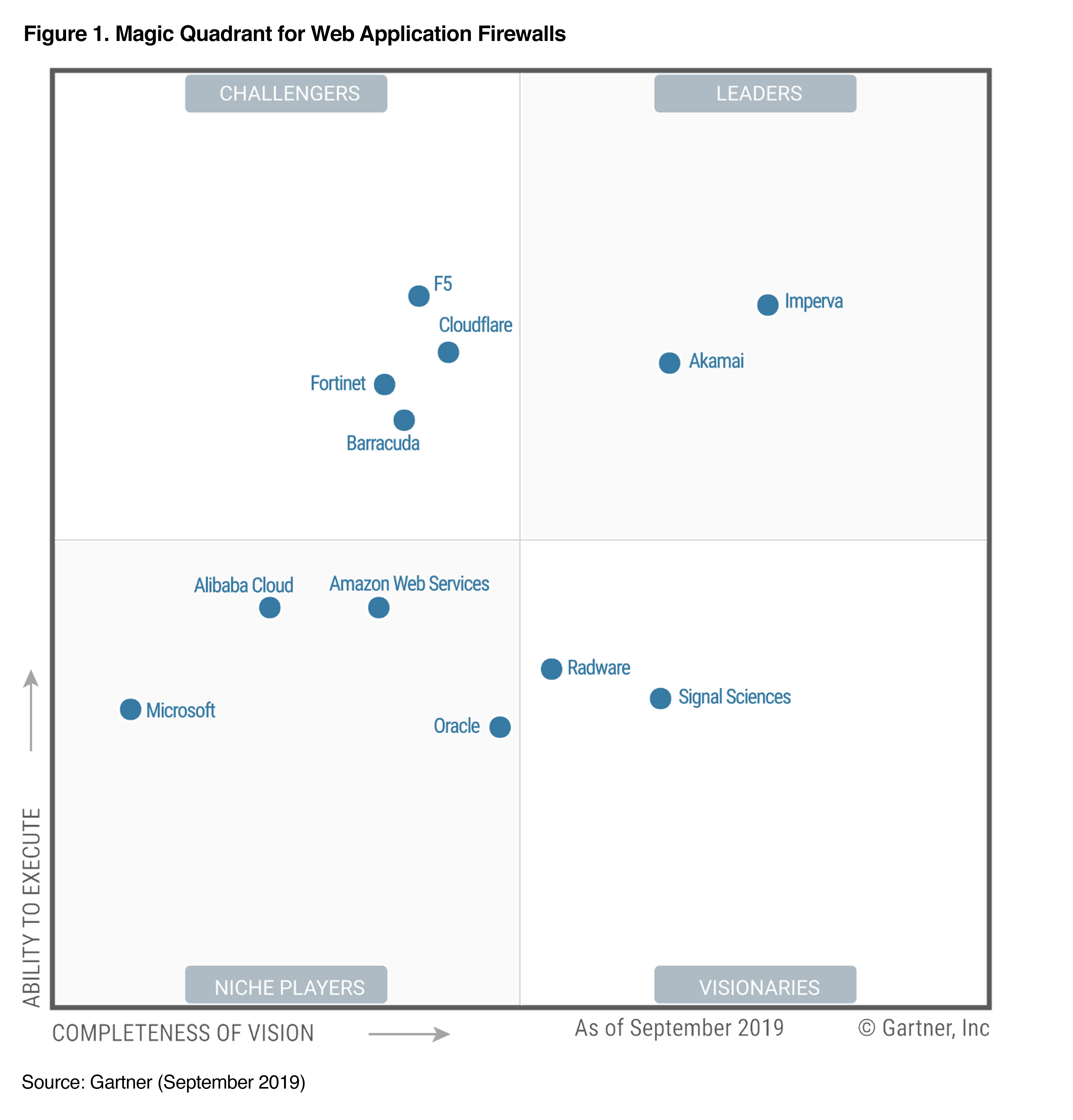
AWS Cloudfront[5] is Amazon's native solution and has proven to be very robust and simple in terms of configuration while advanced features like GeoFiltering , native image compression, dynamic site acceleration etc. are missing amongst the feature set. Azure on the other hand has its own native Azure CDN and also has partnered with Verizon, Akamai to provide a range of solutions with a clean feature set comparison[6]. All of them provide basic web application firewall capabilities and Amazon provides even deeper capabilities with its Enhanced Security package which will be out of scope of this article. For general use cases, especially for simple websites, Cloudfront has proven to be fairly easy to implement and for complex solutions involving a lot of manipulations at the Web layer, Akamai has proven to be leader. Gartner Magic Quadrant in 2019 also calls out Akamai to be a leader in the CDN space.
Key Challenge(Data Migration)
One of the key challenges would be to move data from AEM Servers in AWS to servers launched in Azure. There are several commercial solutions like Netapp's ONTAP [7] which become solutions to be considered if we are to move number of environments and large volumes of data from AWS to Azure. Azure's Site Recovery is yet another Azure's native solution to achieve the same which relies on custom configuration for data movement directly accessing the public end point of Azure Stroage. Relying entirely on TCP/IP and utilizing no cost associated for the first thirty days , there will still be network costs associated with the migration.
In today's date, moving even 1TB of data is not considered large that would warrant to use services such as AWS snowball or Azure Databox, and hence approach of using Site Recovery or Azure Databox may be effective solutions without the anxiety of breaking network connections and losing data while tranfer, and with Azure Databox a workflow can also be scheduled for any delta data syncrhonization.
Summary
Objective of migrating from one cloud service provider to another in current context should be very straight forward as enterprises have started architecting solutions cloud agnostic and a number of instances the migration is typically seamless. This guide summarises the various considerations that would go in to migrate AEM from AWS to Azure.
Reference:
[1] https://helpx.adobe.com/in/legal/product-descriptions/adobe-experience-manager-managed-services.html
[2] https://pages.awscloud.com/Gartner-Magic-Quadrant-for-Infrastructure-as-a-Service-Worldwide.html
[3] https://araihan.wordpress.com/2018/08/02/amazon-ec2-and-azure-virtual-machine-instance-comparison/
[4] https://docs.microsoft.com/en-us/azure/availability-zones/az-overview
[5] https://aws.amazon.com/cloudfront/features/
[6] https://docs.microsoft.com/en-us/azure/cdn/cdn-features
[7] Netapp's ONTAP: https://cloud.netapp.com/blog/data-migration-from-aws-to-azure-reasons-and-challenges
The load balancer is either a classic elastic load balancer or customer tend to use the application load balancer along with basic web application firewall rules attached to it to provide minimum protection to layer 7 traffic at the infrastructure's end point.
The above example serves simply as a reference and by no means refers to an actual customer deployment and the scope of this article would be to use this as a reference and map out a similar architecture in Azure and strategy for movement .
Mapping of Components
Al-Beruni et.al[3] has laid out a nice and easy to understand comparison of instance types between Azure and AWS. The DsV3 series of servers are designed for production workloads offering an ideal balance of compute, network throughput and memory in a similar comparison to the instance type of AWS.
Load Balancing: In comparison to Elastic Load balancer / Application load balancer, Azure AppGateway V2 provides similar capabilities including dynamic scaling, routing traffic at OSI Layer 7 and also similar protection with web application firewall with no additional cost. One of the main points of comparison is the number of sites that can be onboarded to ELB/ALB in comparison to AZGW. AWS ELB is first generation load balancer which does load balancing on OSI layer 4 and we can have only one domain mapping to the ELB while AWS ALB is based on OSI Layer 7, there is a hard limitation of hosting only 20 websites (HTTP&HTTPS) on a single ALB This certainly becomes a challenge with multi tenancy. Azure Gateway can host around 100 websites on the same instance.
One of the biggest draw back with AWS ELB is that customer can only have his WWW or Subdomain mapped to an ELB as they do not provide static IP associated with them. Only a DNS CNAME record can be added for ELB while ALB & Azure AppGateway provides a single static IP that can be added as a DNS A record for 100 different websites in the case of Azure AppGateway & 20 websites for ALB. This clearly is a blessing in disguise for customers who rely on multi-tenancy.
For a long time the concept of availability zones did not exist with Azure [4] and rather it was called update domain / fault domains, now these are integrated into availability zones. The whole requirement became crucial to provide high availability keeping in mind failures of datacenters. Azure also provides the capability of replicating data across the datacenters though keeping in mind AEM architecture, this may not be entirely relevant.
CDN(Content Delivery Network)
AWS Cloudfront[5] is Amazon's native solution and has proven to be very robust and simple in terms of configuration while advanced features like GeoFiltering , native image compression, dynamic site acceleration etc. are missing amongst the feature set. Azure on the other hand has its own native Azure CDN and also has partnered with Verizon, Akamai to provide a range of solutions with a clean feature set comparison[6]. All of them provide basic web application firewall capabilities and Amazon provides even deeper capabilities with its Enhanced Security package which will be out of scope of this article. For general use cases, especially for simple websites, Cloudfront has proven to be fairly easy to implement and for complex solutions involving a lot of manipulations at the Web layer, Akamai has proven to be leader. Gartner Magic Quadrant in 2019 also calls out Akamai to be a leader in the CDN space.
Key Challenge(Data Migration)
One of the key challenges would be to move data from AEM Servers in AWS to servers launched in Azure. There are several commercial solutions like Netapp's ONTAP [7] which become solutions to be considered if we are to move number of environments and large volumes of data from AWS to Azure. Azure's Site Recovery is yet another Azure's native solution to achieve the same which relies on custom configuration for data movement directly accessing the public end point of Azure Stroage. Relying entirely on TCP/IP and utilizing no cost associated for the first thirty days , there will still be network costs associated with the migration.
In today's date, moving even 1TB of data is not considered large that would warrant to use services such as AWS snowball or Azure Databox, and hence approach of using Site Recovery or Azure Databox may be effective solutions without the anxiety of breaking network connections and losing data while tranfer, and with Azure Databox a workflow can also be scheduled for any delta data syncrhonization.
Summary
Objective of migrating from one cloud service provider to another in current context should be very straight forward as enterprises have started architecting solutions cloud agnostic and a number of instances the migration is typically seamless. This guide summarises the various considerations that would go in to migrate AEM from AWS to Azure.
Reference:
[1] https://helpx.adobe.com/in/legal/product-descriptions/adobe-experience-manager-managed-services.html
[2] https://pages.awscloud.com/Gartner-Magic-Quadrant-for-Infrastructure-as-a-Service-Worldwide.html
[3] https://araihan.wordpress.com/2018/08/02/amazon-ec2-and-azure-virtual-machine-instance-comparison/
[4] https://docs.microsoft.com/en-us/azure/availability-zones/az-overview
[5] https://aws.amazon.com/cloudfront/features/
[6] https://docs.microsoft.com/en-us/azure/cdn/cdn-features
[7] Netapp's ONTAP: https://cloud.netapp.com/blog/data-migration-from-aws-to-azure-reasons-and-challenges









